Big Data
Purpose
This page covers notes, labs, personal setup items, deviations, etc. covered in the Design Data Integration Learn module.
- Purpose
- Storage Comparison
- Data Factory vs Azure Synapse
- Azure Data Factory
- Azure Data Lake
- Azure Databricks
- Azure Synapse Analytics
- Data Paths
- Azure Stream Analytics
Storage Comparison
| Compare | Azure Data Lake | Azure Blob Storage |
|---|---|---|
| Data types | Good for storing large volumes of text data | Good for storing unstructured non-text based data like photos, videos, and backups |
| Geographic redundancy | Must manually configure data replication | Provides geo-redundant storage by default |
| Namespaces | Supports hierarchical namespaces | Supports flat namespaces |
| Hadoop compatibility | Hadoop services can use data stored in Azure Data Lake | By using Azure Blob Filesystem Driver, applications and frameworks can access data in Azure Blob Storage |
| Security | Supports granular access | Granular access isn’t supported |
Overall comparison summary:
- Azure Data Lake Storage serves as the central storage repository for your data, including raw, unprocessed data.
- Azure Data Factory ingests, prepares, and moves data into and out of Data Lake Storage, ensuring it’s ready for analysis.
- Azure Synapse Analytics analyzes and processes data stored in Data Lake Storage, deriving insights and running advanced analytics on the data.
Data Factory vs Azure Synapse
| Compare | Azure Data Factory | Azure Synapse Analytics |
|---|---|---|
| Data sharing | Data can be shared across different data factories | Not supported |
| Solution templates | Solution templates are provided with the Azure Data Factory template gallery | Solution templates are provided in the Synapse Workspace Knowledge center |
| Integration runtime cross region flows | Cross region data flows are supported | Not supported |
| Monitor data | Data monitoring is integrated with Azure Monitor | Diagnostic logs are available in Azure Monitor |
| Monitor Spark Jobs for data flow | Not supported | Spark Jobs can be monitored for data flow by using Synapse Spark pools |
Azure Data Factory
Used to move and transform data at scale via pipelines which ingest data from different sources into a single data store. A middle layer for ingesting, storing, collating, transforming and making data ready for other purposes.
There are four major workflow steps in Azure Data Factory
- Connect and collect
- Transform and enrich (via Azure Databricks and Azure HDInsight Hadoop)
- CI/CD via Azure DevOps to hand off the data to another service (Power BI, ML)
- Monitor the pipeline
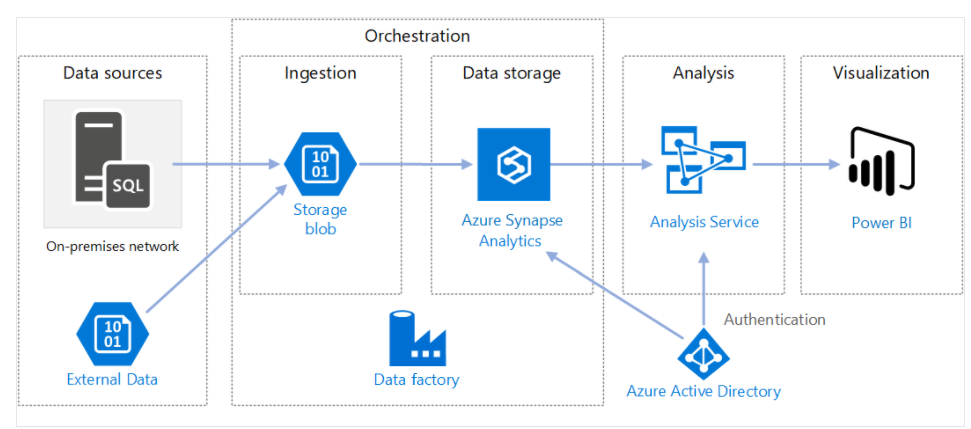
Data Factory Considerations
- Target audience are the Big Data communites and the relational data warehousing via SQL Server Integration Services (SSIS)
- Graphical interface for setting up pipelines via low code/no code process
- 100% serverless infrastructure
- Batch Processing vs other Azure solutions (Azure Synapse for real-time)
- It moves and transforms data, it’s not designed for analytics tasks.
Azure Data Lake
Blob storage on steroids.
- Stores any type of data
- Designed to work with Hadoop and HDFS
- Supports RBAC, POSIX and ACLs for authorization
- Data redundancy via the Blob replication models (ZRS, GRS, etc.)
How it works:
- Ingest data in real time
- Ad-hoc: AzCopy, Azure CLI, Powershell and Azure Storage Explorer
- Relational: Data Factory, Azure Cosmos DB, SQL, etc.
- Streaming ingestion from: apache storm, Azure HDInsight, Stream Analytics, etc.
- Access data
- Easiest is via Storage Explorer but PowerShell, Azure CLI, HDFS CLI and other options work
- Access control
- Manage access via RBAC or ACL
Data Lake Requirement Scenarios
- Provide a data warehouse on the cloud for managing large volumes of data.
- Support a diverse collection of data types, such as JSON files, CSV, log files, or other formats.
- Enable real-time data ingestion and storage.
- Output to various sytems
Azure Databricks
Azure Databricks provides data science and engineering teams with a single platform for big data processing and Machine Learning. It is 100% based on Apache Spark, an open-source cluster-computing framework.
Made of of two planes:
- Control Plane: hosts jobs, notebooks (with results), web application, hive metastore and ACLs.
- Managed by Microsoft in collaboration with Databricks. Does not reside in Azure subscription (think Elastic stack collaboration)
- Data Plane: contains all of the runtime clusters hosted within the workspace. All data processing and storage exists within the Azure subscription and no processing ever happens within the Microsoft/Databricks subscription.
Offers three environments
- Databricks SQL: for analyts running SQL queries on data lake.
- Databricks Data Science and Engineering
- Workspace for collaborating between data engineers, data scientists and ML engineers
- Big data pipelines pull in data and then process via Spark
- Databricks ML: end-to-end ML environment for experiment tracking, model training, etc.
Databricks Requirement Scenarios
- Apache Spark
- Integration with rea-time third party tools like Kafka and Flume for processing streaming data
- Unify data without centralization
Databricks Considerations
- Data preparation: Create, clone, edit clusters of unstructured data. Transform them into jobs and deliver the results
- Insights: Build recommendation engines, analysis and intrusion detection (behavior heuristics)
- Collaborative productivity: use for cross-specialty collaboration (data engineers, analysts, scientists)
- Great option for ML
Azure Synapse Analytics
- Azure Synapse Analytics is optimized for high-performance analytics and processing of large datasets
- It can handle massive volumes of data and complex analytical queries efficiently due to the massive parallel processing architecture
- Uses a technology named PolyBase to query and retrieve data from relational and non-relational sources
- save the data read in as SQL tables inside the Synapse service
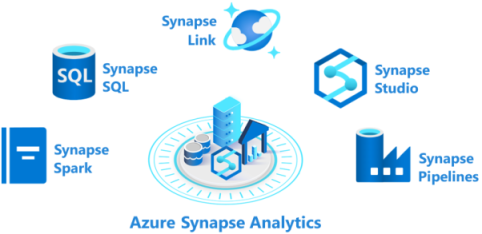
Comprised of:
- Azure Synapse SQL pool: offers serverless and dedicated models in a node-based architecture
- Azure Synapse Spark pool: cluster of servers that run Apache Spark directly (vs Databricks and the collaboration setup)
- Azure Synapse Pipelines: Leans on the abilities of Azure Data factory. Pipelines are workflows for orchestrating data movement and transformation.
- Azure Synapse Link: connect to Cosmos DB for near real-time analytics of the data in Cosmos
- Azure Synapse Studio: Web-based IDE to create, manage and work with all of the Synapse ecosystem
- Consider variety of data sources. When you have various data sources that use Azure Synapse Analytics for code-free ETL and data flow activities.
- Consider Machine Learning. When you need to implement Machine Learning solutions by using Apache Spark, you can use Azure Synapse Analytics for built-in support for AzureML.
- Consider data lake integration. When you have existing data stored on a data lake and need integration with Azure Data Lake and other input sources, Azure Synapse Analytics provides seamless integration between the two components.
- Consider real-time analytics. When you require real-time analytics, you can use features like Azure Synapse Link to analyze data in real-time and offer insights.
Data Paths
Warm Data Path
- Warm Data: data is analyzed as it flows with stream processing near real time.
- Data saved to wam storage and then pushed to analytics compute
- Stream Analytics is popular processing option
- Warm storage can use services Azure SQL Database and Azure Cosmos DB
A usage example would be an E-commerce company optimizing it’s supply chain operations. Customer orders, inventory levels, supplier data, and historical sales data are stored and processed in a scalable data warehouse, enabling near-real-time analysis and decision-making. Machine learning algorithms forecast demand, optimize inventory replenishment, and improve shipping efficiency by analyzing historical data. The retailer achieves improved inventory management, reduced shipping costs, and enhanced customer satisfaction through accurate delivery estimates and fewer shipping delays.
Cold Data Path
- Cold data consists of a batch layer and a serving layer for long-term views
- Batch layer pre-calculates combined views to forecast query responses over long periods.
- Cold path includes long-term data from storage solutions (Azure storage, Data Lake, Files, Queues and Tables)
- Can be a combination of all of the above
Usage scenarios would really be any, “over time” analytics as we’re looking at “historical” (not real-time) data
Hot Data Path
Hot data is real-time, time sensitive data processing. e.g. Security analytics of user behavior.
Azure Stream Analytics
Stream processing is ingesting data streams, analyzing and delivering useable insights.
- Fully managed PaaS offering
- Real-time (not near real-time like Synapse) analytics and event-processing engine.
- Supports multiple data sources (IoT, sensors, social media feeds, etc.)
- Data Streams for monitoring equipment sensors, utility providers, etc. track change over time
- Event processing draws conclusions from the data

Process:
- Input
- From multiple azure services like Event Hubs, IoT Hub or Blob Storage
- Query
- Analyze with Stream Analytics
- Reference other data (Warm Data path)
- Output
- Data Storage/Warehouseing
- Visualization dashboards
- Event based services like Functions, Service Bus, Event Hubs
Requirement Scenarios
- Analyze real-time telemetry streams from IoT devices.
- Build web logs and clickstream analytics.
- Create geospatial analytics.
- Execute remote monitoring and predictive maintenance of high value assets.
- Perform real-time analytics on data.
Stream Analytics Considerations
- PaaS for minimal overhead
- Low cost consumption model with automatic scaling
- For ultra-low tatency consider Stream Analytics on IoT Edge or Azure Stack
- High performance via partitioning allows for parallelized workloads and multiple streaming nodes
- Millions of events every second
- Ultra-low latencies
- Secure via encrypting all ingress and egress with TLS 1.2.
- Checkpoints are also encrypted
- Does not store incoming data because it’s all processed in-memory