High Availability and DR
Purpose
This page covers notes, labs, personal setup items, deviations, etc. covered in the Design Business Continuity Solutions Learn module.
HA and DR
High availability is the design concept of resiliency and redundancy and is typically scoped to a deployment or small geographical region. A piece of infrastructure should be able to recover from basic failures, and when it cannot, another system/process should be ready and waiting to seamlessly take its place.
Disaster recovery focuses on both concepts but leans heavily into data protection, recovery times and recovery points spanning a larger geographical region. The entire West US data center is down, what other region do we recover to? how and when do we recover to?
Two key concepts are thrown around quite a bit with their acronyms showing up constantly in the backup and recovery world; RTO and RPO.
- Recovery Time Objective is how quickly do we need everything back up and running? The server just died - is it coming back up in 10 minutes, a few hours, what?
- Recover Point Object is how granular your snapshots/backups are - how much data can you lose? If you backup once a day at 11:00PM and the server dies at 9:00PM you’ve lost an entire days worth of work/data.
Understanding the realistic expectations for both points, designing for it and TESTING for it is imperative for every company. There are multiple points that should be considered when determining each objective.
- What is the cost of downtime? If the business loses $X every hour then the money spent on HADR should be proportional to the potential loss.
- Consider bottlenecks - the RTO is limited by the slowest system to come back online. Taking all of the interlocking pieces into account sets an accurate expectation.
- What systems are capable of automating for failover? Which systems/processes must be manual?
- These should be constantly reviewed for possible solutions as technology changes
- How long do recoveries actually take?
- What stakeholders are involved in making these decisions? Who is responsible for maintaining P&P, performing tests, etc.?
IaaS vs PaaS
The example in the learn module is around SQL databases which is a fair example. Know that there are other options that may/may not support multi-system clustering and the appropriate stakeholders should be involved in designing around those limitations.
IaaS involves running SQL inside of a VM, which has it’s own overhead but more granular (and manual) control around installation and configuration of the high availability and disaster recovery. PaaS however has a limited number of of the solutions built in and they just need to be enabled.
Failover Cluster Instances
FCI = Failover Cluster Instance
FCIs require the use of Active Directory Domain Services (AD DS) and Domain Name Services (DNS), so that means AD DS and DNS must be implemented somewhere in Azure for an FCI to work.
- Run on shared storage NOT replicated storage
- It’s basically like an Elasticsearch node. There’s a primary front-end node that communicates with user land, orchestrates sessions, etc. which can shuffle to another node during failover during the recovery process.
- Failover is not seamless but applications can be created/designed to make it appear so (caching?)
- FCIs can use Storage Replica as a native DR option
- Eliminates using log shipping (journals?) or Always On Availability Groups (AGs)
FCI is configured when SQL is installed and standalone installations cannot be converted to a failover cluster instance. It’s very similar to a Kubernetes cluster where there is a unique name and IP address separate from the servers comprising the cluster. That “front end” is what users and applications are configured to interface with. Azure based FCI’s must included an internal load balance which orchestrates the application/user level connection to the FCI’s unique name/IP.
This is a blatant copy+paste from the site, but it’s pretty important:
FCIs require one copy of a database, but that is also its single point of failure. To ensure another node can access the database, FCIs require some form of shared storage. For Windows Server-based architectures, this can be achieved via:
- Azure Premium File Share
- iSCSI
- Azure Shared Disk
- Storage Spaces Direct (S2D)
- or a supported third-party solution like SIOS DataKeeper.
FCIs using Standard Edition of SQL Server can have up to two nodes.
FCI Single Region Example
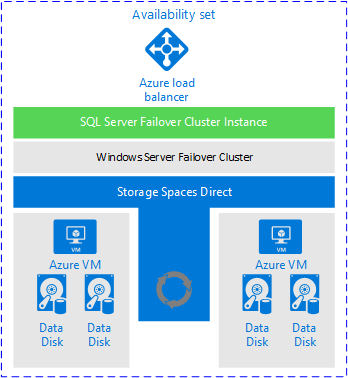
- Popular in lift-and-shift scenarios as FCI was/is common on-prem
- Azure Shared Disk, Storage Spaces Direct, and other storage solutions can provide for the shared storage requirement
- Provides uptime during patching scenarios
Availability Groups
AGs provide database redundancy by automatically shipping data to a secondary database. If a failure occurs, just move on to the secondary DB.
- They have a quicker failover time compared to FCI
- They don’t require shared storage as they each have a copy of the data
- Standard Edition is a single pair (primary and secondary) of databases
- Enterprise Edition consists of nine DBs. One primary and eight secondary.
- Replicas are initialized from a backup of the database OR in SQL Server 2016 you can use automatic seeding (stream data to the replica in real time)
AGs also have a listener on another layer, however, it doesn’t have to be used and connections can be made directly into the primary database.
- Listener requires an internal load balancer as well
- Enterprise Edition can set secondary replicas as read only access
- Use the replica’s for other compute functions to keep the primary performance for user facing applications
- Backup from the replica
- Perform consistency checks against the replica
- Use the replica’s for other compute functions to keep the primary performance for user facing applications
AG Single Region Example
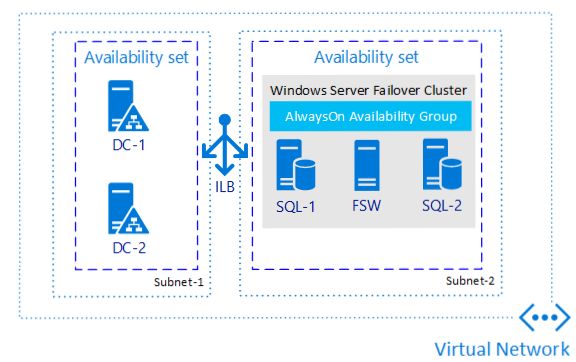
- Duplicate copies of the data across multiple VMs
- Easy, standard method for data access (in read-only replica setups)
- Stays up during patching scenarios
- No shared storage like FCI
AG Multi-region Or Hybrid Example

- This architecture is a proven solution; it is no different than having two data centers today in an AG topology.
- This architecture works with Standard and Enterprise editions of SQL Server.
- AGs naturally provide redundancy with additional copies of data.
- This architecture makes use of one feature that provides both HA and D/R
- Basically a Host:nSmartLane setup with SmartLanes in different regions
AG Distributed Availability
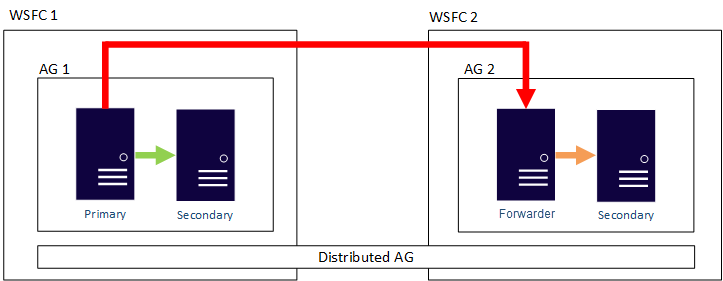
- This architecture separates out the WSFC as a single point of failure if all nodes lose communication
- In this architecture, one primary is not synchronizing all secondary replicas.
- This architecture can provide failing back from one location to another.
- Essentially daisy chaining a SmartLanes off of each other
Log Shipping
- Provides database-level protection like AGs
- All of the infrastructure, networking, DNS, etc. must be accounted for via other methods
- It’s basically a warm spare
- Create an initial copy of the primary SQL database
- Set the copy into a loading state (STANDBY or NORECOVERY)
- Simply put - the spare ingests the log data, constantly keeping the DB up to date
Azure HADR Options For VMs
Azure provides three main options to enhance availability for IaaS deployments. All three of these options are external to the virtual machine (VM) and don’t know what kind of workload is running inside of it.
- Availability Sets
- Ensure VMs don’t run in the same fault domains (hardware stack) and update domains (maintenance groups)
- No visibility on VM workload
- Does NOT protect against in-guest failures (DB, OS, etc.)
- Each tier or layer of a solution should placed across availability sets
- Availability Zones
- Multiple data centers (zones) in a region
- Protect against DC failures
- Minimal (but measurable) 1ms latency between zones
- Not just for VMs but also Azure SQL Database
- Azure Site Recovery
- Absolutely amazing piece of tech that makes DR drills a breeze
- Limited RPO times make this a true disaster based tool
- Can mirror an entire infrastructure deployment into another region
- RTO of two hours (can be shorter)
- Pair it with more granular data backup operation for a quicker DR turnaround
- Offers two tiers
- Standard for low-cost with limited capabilites
- Premium for better performance and features
PaaS Offerings
PaaS is great, but it is limited by the options presented by Azure. Stakeholders need to be aware of the limitations to prevent gotchas further down the road when a DBA wants to try something new/different.
SQL options are:
- Azure SQL Database
- geo-replication
- autofailover groups
- Azure SQL Database Managed Instance
- autofailover groups
Other options:
- Azure Database for MySQL has a SLA of 99.99 (so no downtime)
- Node level problems are automatically failed over
- Transactional changes are written synchronously
- New automatic nodes attach to the data storage
- All connections are dropped
- Necessary to code for retry logic in applications
- Azure Database for PostgreSQL is similar to MySQL with the exception of Citus, a scale-out solution. If enabled:
- Standby replica for every node of a server group
- increases cost as it doubles the number of servers in teh group
- Original node fails > standby immediately takes its place
- Data is synced via the PostgreSQL streaming replication
- Also requires retry logic in applications
Both Azure DB for MySQL and PostgreSQL support read replica (like availability groups) which are shipped to another region.
Hybrid Solutions
These are based in IaaS which then populate to PaaS solutions, possibly across cloud platforms. You can project on-prem into Azure, AWS, GCP, etc. as long as the networking cornerstone is accounted for.
Backup and Recovery
A companion piece (or cornerstone depending on architecture) of HADR. The planning phase includes similar POIs.
MTTR = Mean Time To Recovery = average time it takes to restore MTBF = Mean Time Between Failures = how long it lasts between failures
- What workloads are running? What are their availability requirements? Bottle necks?
- What are the availability metrics? How long do components last between outages? How quickly can it be restored?
- What is the application’s RTO? What about RPO? What is the scope of the recovery?
- What is the cost impact of the system(s) being down? What is it worth to reduce downtime?
- What are the SLA targets?
Perform your risk assessments! There are real value in these and they are required by multiple compliance policies for a reason.
Azure Backup
Is a service to protect cloud VMs/workloads along with on-prem systems/workloads.
- On-Prem uses a few different agents
- Microsoft Azure Recovery Services (MARS)
- Backs up files, folders and system state of a Windows system
- NOT a bare metal backup tool
- System Center Data Protection Manager (DPM)
- Microsoft Azure Backup Server (MABS)
- Protect on-prem VMs at the hypervisor level
- Microsoft Azure Recovery Services (MARS)
- Azure VMs
- Requires backup extensions in the VM 3
- The MARS agent can be installed to backup files, folders and system state
- Requires backup extensions in the VM 3
- Azure Files
- Backup to a storage account
- SQL Server in Azure VMs
- SAP Hana databases in Azure VMs
- Azure Backup has specialized offerings for database workloads like SQL Server and SAP HANA. These offerings are workload-aware, provide 15-minute RPO (recovery point objective), and allow back up and restore of individual databases.
Azure backs up to two different types of storage vaults
- Azure Backup vault: Azure Backup vaults are used with Azure Backup only.
- Supported data sources include Azure Database for PostgreSQL servers, Azure blobs, and Azure disks.
- Azure Recovery Services vault: can be used with Azure Backup or Azure Site Recovery.
- Supported data sources include Azure virtual machines, SQL or SAP HANA in an Azure virtual machine, and Azure file shares.
- You can back up data to a Recovery Services vault from Azure Backup Server, Azure Backup Agent, and System Center Data Protection Manager.
There are a few design considers when it comes to vaults.
- Organization: most likely match to the number of subscriptions
- Use separate vaults for Azure Backup and Azure Site Recovery
- Use Azure Policy: define your vault settings via policy and scope it to a vault(s)
- Protection: Use RBAC to protect the vault data
- Redundancy: Use storage account types (ZRS, LRS, GRS, etc.) as appropriate
- Involve stakeholders on how important/mission critical/valuable the data is
- Take into account your HA and DR deployments
Blob Backups
- Stored in the source Azure storage account (adjacent to blob data)
- Operational backup supports blob versioning
- Operational backup provides continuous backups
- Operational accounts for all changes and allow for granular point in time restores
- Soft delete is available for blobs and containers
- Default is 7 day retention
- Configurable between 1 and 365 days
- Scopes to an individual blob, snapshot, container or blob version
- Container soft delete doesn’t protect against the deletion of a storage account, but only against the deletion of containers in a storage account.
Azure Files
- You can snapshot file shares which can act as a general backup for DR
- Backs up to Azure Recovery Service vault
- Snapshot is performed at the top level of a file share and includes all sub files and folders
- Only deltas are stored
- Preferred management method is via Azure Backup and RSV
- Azure Backup keeps the metadata about the snapshot backup in the Recovery Services vault, but no data is transferred.
- Provides a fast backup solution that has built-in backup and reporting
- Automatically enables soft delete
Considerations include:
- Alerts and reporting
- Self service restore grants users the ability to restore files on their own
- On-demand backups can be triggered by users as needed
- Organize according to how you intend to store
- public: public, private:private, etc. and include retention as part of the scheme
- Snapshot before major events
Azure VMs
- Two part process: snapshot and then move to RSV
- three different levels: application, system and crash
- heh - two different defaults defined in the docs
- Consider the following:
- Backup times and data transmit traffic
- GFS backup periods are typical
- Create policies to ensure that settings are defined and scoped correctly
- Lean on tags to target across subscriptions and RGs
- Include backup policies in your risk reviews!
- Don’t store too many in a single storage account as multiple, concurrent restorations with slow down the restore process
- e.g. if constantly restoring X VMs use X number of storage accounts
- Test the backups on a consistent schedule
- Document any requested backups as well as they can be useful when providing proof during compliance reviews
- Watch out for Cross Region Restore
- My experience is that this is enabled by default contrary to the docs
- It’s useful but expensive
- Ensure that backups are using CRR as needed
Azure SQL Backups
This is pretty slick, as long as it fits your use case.
- Full backups: In a full backup, everything in the database and the transaction logs is backed up
- SQL Database makes a full backup once a week
- Differential backups: In a differential backup, everything that changed since the last full backup is backed up
- SQL Database makes a differential backup every 12 - 24 hours
- Transactional backups: In a transactional backup, the contents of the transaction logs are backed up
- If the latest transaction log has failed or is corrupted, the option is to fall back to the previous transaction log backup
- Transactional backups enable administrators to restore up to a specific time, which includes the moment before data was mistakenly deleted
- Transaction log backups every five to 10 minutes
- Are not immutable (oof)
Backups are retained for 35 days by default. This is… questionable due to a lot of compliance requirements.
- It can be extended via the long-term retention (LTR) feature
- RA-GRS blobs last up to 10 years
Azure Site Recovery
I have quite a bit of experience with this one and I absolutely love it. There are minor gotchas to be aware of but it’s a really great tool. It can also be used as a lift-and-shift if needed.
- Based on the idea of a primary:secondary region pair
- Azure pairs them automatically, no choices here
- Replicate:
- Azure VMs
- on-prem VMs
- Workloads
- Automate tasks
- Automatic failover tests on a schedule
- Monitor the recovery process
- Bring up VMs in specific order
- DR tests don’t interrupt live replication
- RTP and RPO targets
- Continuous replication for Azure and VMware VMs
- Replication can be as low as 30 seconds for replicated Hyper-V VMs
- Plan for failovers and complete the failover gracefully
- Native support for SQL Server AlwaysOn